
Amazon Redshift is a cloud Data warehouse solution for querying and analyzing data. In this blog, we will discuss how Redshift delivers fast query performance.
Amazon Redshift provides different types of instances to maximize speed for performance-intensive workloads. It provides fast performance for datasets varying in size from gigabytes to petabytes. It is easily scalable as per your needs. You can choose a different number of nodes for different types of workloads.
Redshift can be integrated with many third-party analytic tools and SQL clients.
Other AWS services like Amazon Sagemaker, Amazon Athena, and Amazon EMR also use Redshift to do further analysis of data.
You can also connect Amazon Quicksight and other third-party BI tools with Redshift for visualizing your data and getting more granular insights.
Redshift is easy to manage and has some automated maintenance strategies. So, that the customer can concentrate on his data insights and not have to worry about data warehouse management.
Amazon Redshift has countless features which make it suitable for analyzing data insights. All you have to do is to start working on it and then you will understand the flexibility of Redshift.
Let’s do some hands-on with Amazon Redshift to get a better idea.
Go to services, then click on Amazon Redshift.
And, the below window will open up. Now click on Create cluster.

Here, you can mention the details as per the columns defined.
In the cluster identifier, you have to mention the cluster name. Choose Production or Free trial as per your choice.
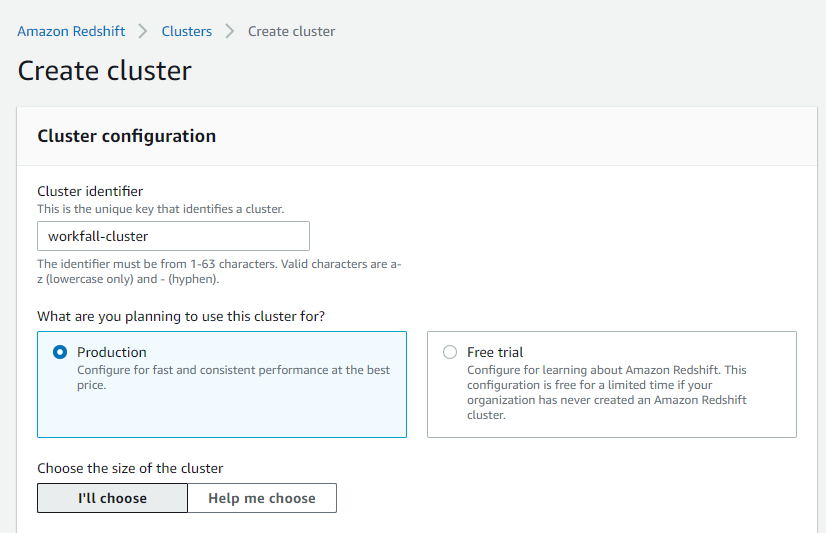
We will choose the Node type as dc2.large and enter the number of nodes as 1. Below you will get the configuration summary.

In the database configurations menu. Mention the name of the database. Also, mention the Master user name and Master user password.

In Cluster permissions, choose an IAM Role for your redshift. This role will allow Redshift to access the AWS services.

You will need a Cluster subnet group in the next step. So, go to the navigation bar of the redshift. You will see a subnet group mentioned. Click on it and you are directed to this page. Now, click on Create cluster subnet group.

Mention the details below.
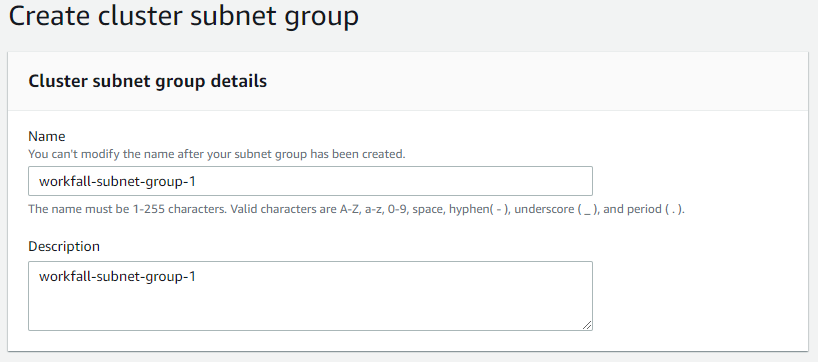
Add your VPC and then click on add all the subnets of this VPC.
All the subnets of the VPC will be added below. Now, click on create.

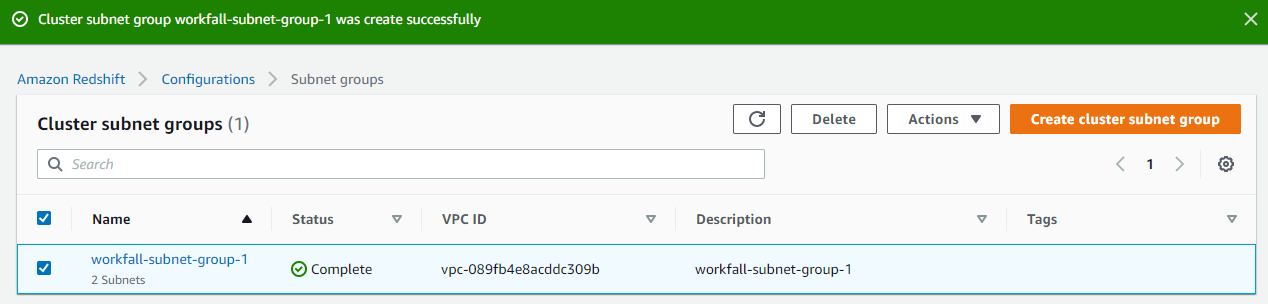
The cluster subnet group is created successfully.
Now, go back to your Redshift window, and here you can mention the VPC name, security group, and cluster subnet group.

Now, click on create a cluster.

Our Redshift cluster is created successfully.

Now, we have to connect our database with the SQL server. Amazon Redshift provides an inbuilt SQL editor to connect you with.
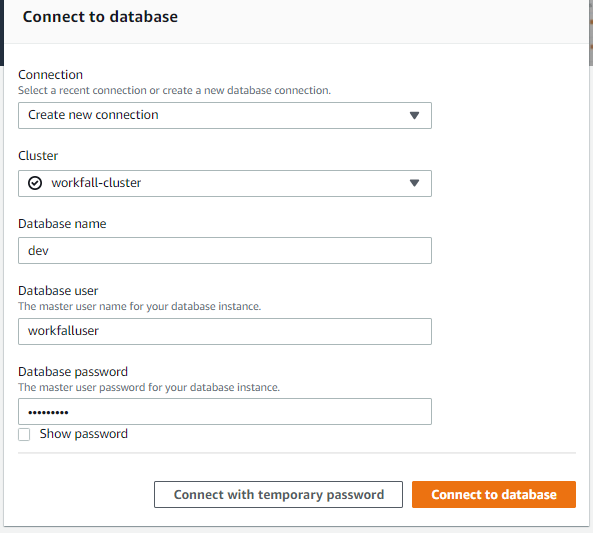
Once, you will fill in all the connection details. You will be redirected to the Query editor.
We can create a table in our database. After mentioning the below query, click on Run.

Table fruits will be created. Now, you can insert values into the table as per below.
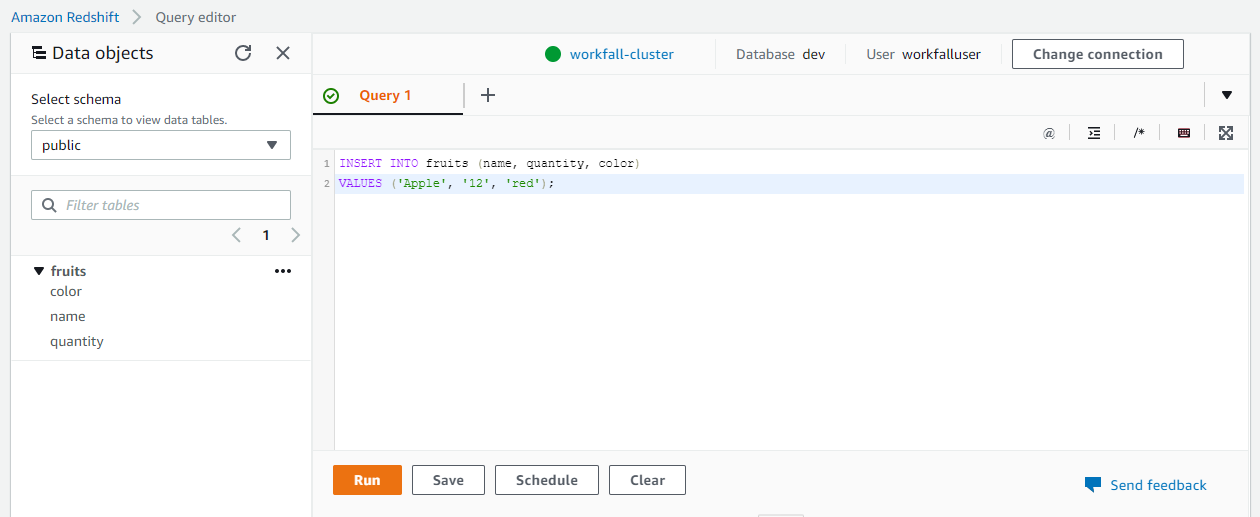
You can see the values have been added to the table.

Like this, we can add more data to the table.

And the data is automatically added to the table.

This is how we can create an Amazon Redshift database cluster and query into our database.
Amazon Redshift has many extensive use cases that could help data scientists and developers to solve real-time problems.
Hope this information is helpful. We will keep sharing more about how to use new AWS services. Stay tuned!
Meanwhile …
Keep Exploring -> Keep Learning -> Keep Mastering
At Workfall, we strive to provide the best tech and pay opportunities to kickass coders around the world. If you’re looking to work with global clients, build cutting-edge products and make big bucks doing so, give it a shot at workfall.com/partner today!


