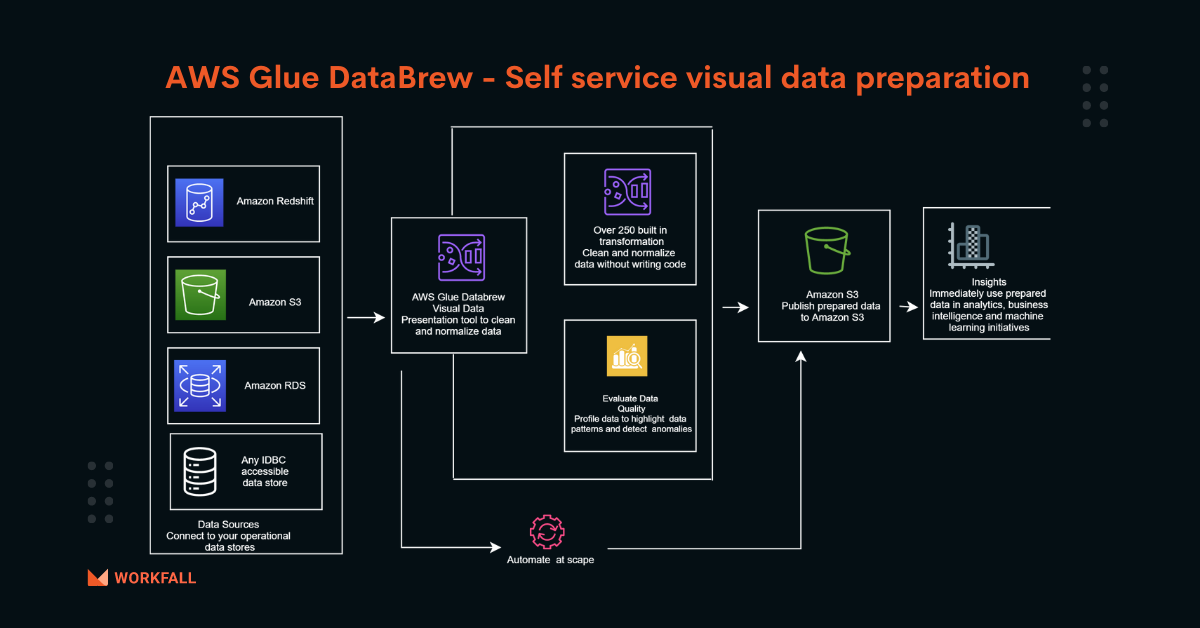
AWS Glue is a serverless managed service that prepares data for analysis through automated ETL processes. This is a simple and cost-effective method for categorizing and managing big data in the enterprise. It gives businesses a data integration tool that prepares data from multiple sources and organizes it in a central repository where it can be used to make business decisions.
AWS Glue cuts the time it takes to analyze and present data in half, from months to hours. AWS Glue provides both code-based and visual interfaces to make this magic happen.
AWS just released AWS Glue DataBrew, a no-code visual data preparation tool that helps users clean and normalizes data without writing code, to improve ETL capabilities using AWS Glue.
Let’s explore it!
Any CSV, Parquet, JSON, or .XLSX data saved in S3, Redshift, the Relational Database Service (RDS), or any other AWS data store accessible via a JDBC connector can be used by the DataBrew.
It also includes over 250 pre-built transformations for automating data preparation activities such as detecting abnormalities in data, standardizing data formats, and rectifying erroneous values, among other things. You can use the data for analytics and machine learning right away after it’s been prepared.
Let’s have a look at this service with a simple experiment that we’ve divided into three parts:
1. Create an S3 bucket and put a sample in it.
2. Provide DataBrew read permissions to an S3 bucket via a CSV file.
3. To visually explore, comprehend, integrate, clean, and normalize data in a dataset, create a DataBrew project.
1. Create a S3 bucket & upload a sample .CSV file
We’ll use an S3 bucket and a.CSV file in this example. We have one sample data file that we will upload to an S3 bucket and make publicly accessible.
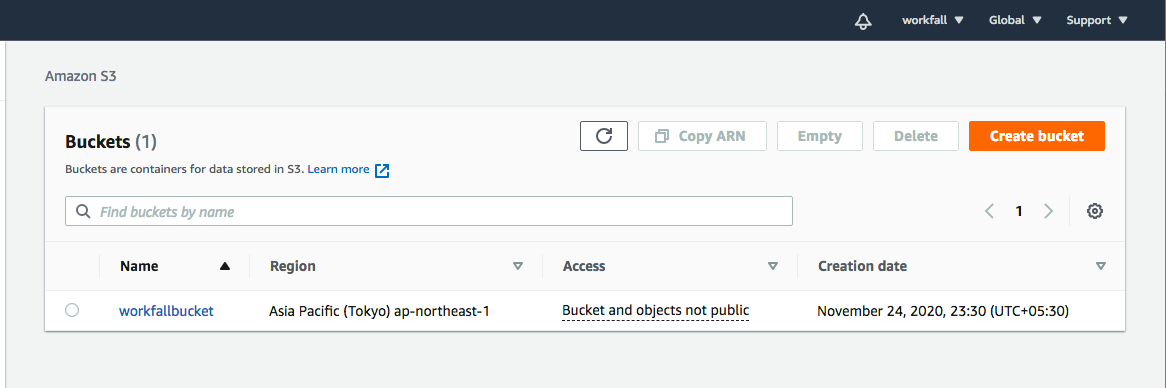
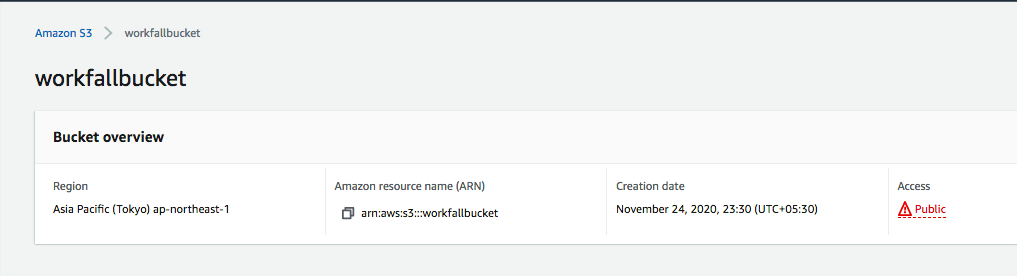
So, let’s head over to the AWS UI and quickly establish a bucket called “workfallbucket” and make the necessary rights and policy adjustments.
(Please note that the AWS Glue DataBrew service is only available in the areas listed below.) So make sure the region and bucket being formed are in the same area before commencing this activity.)
For this experiment, we’ll use the Asia Pacific (Tokyo) area and construct this bucket under that region, as seen in the picture below:
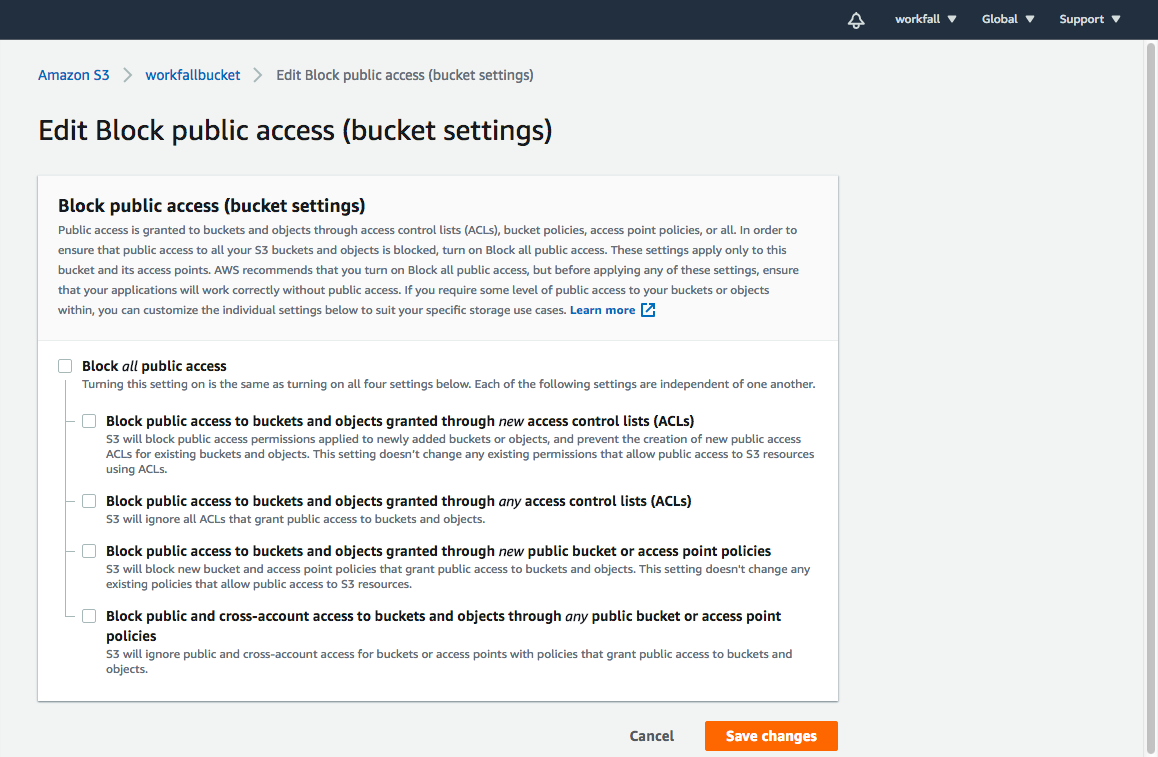
Now, let’s make our bucket public by unselecting the “block all public access” checkbox. Click on Save changes. (Refer to the following image)
let’s upload a data file as an object and make this file public by applying the required policy setting.
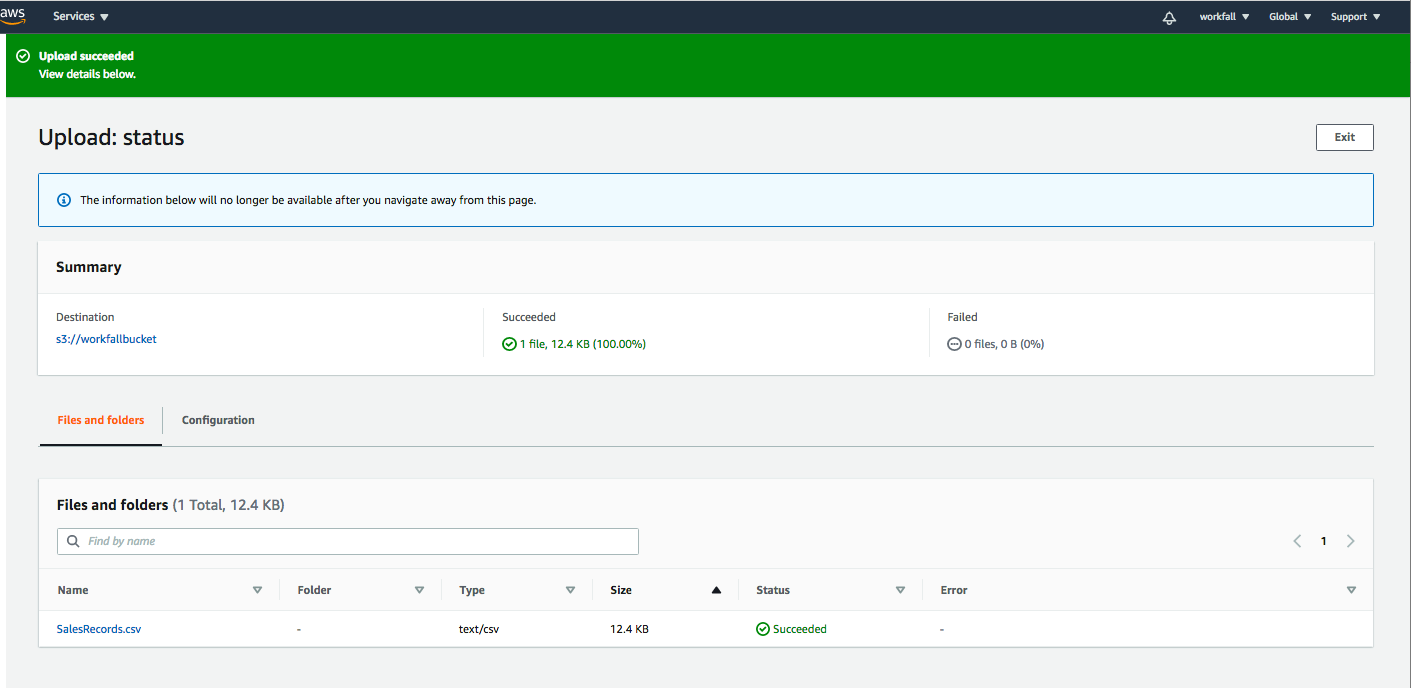
Click on the file name and you will get the following screen
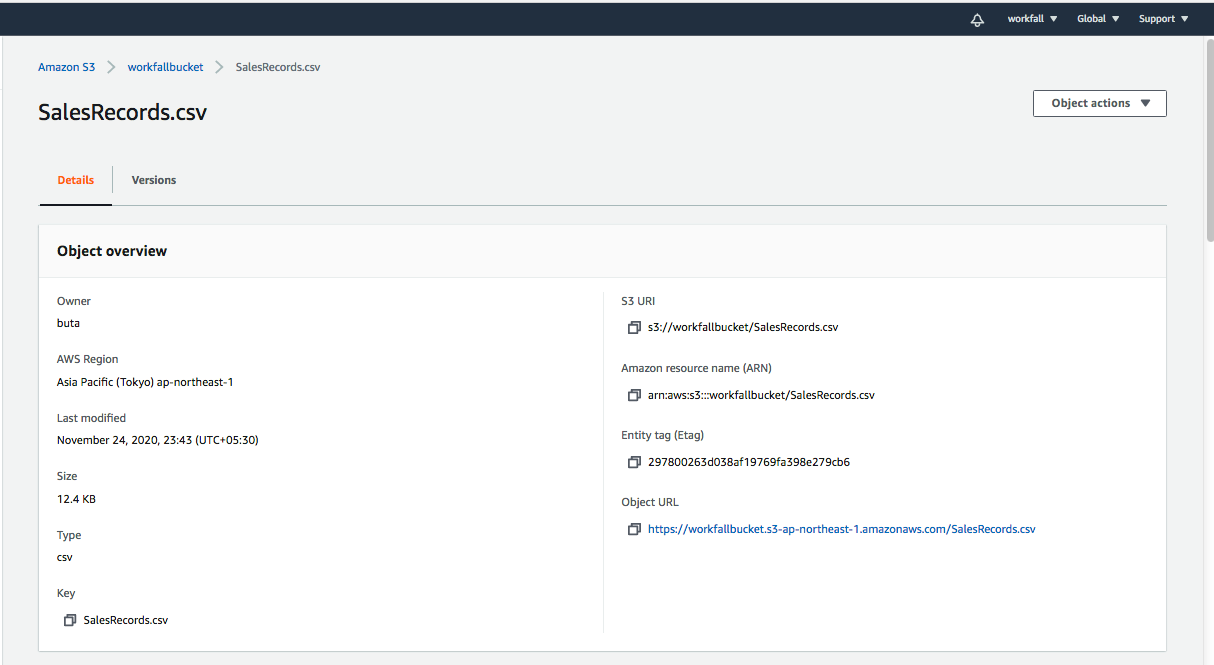
Now if you will try to access the Object URL of the file, it will show you the following error message

Let’s do the required changes in the file policy to access it publicly. To do this, go to the permission tab of the bucket and edit the bucket policy. You can generate the required policy using a policy generator or write it in the policy window.
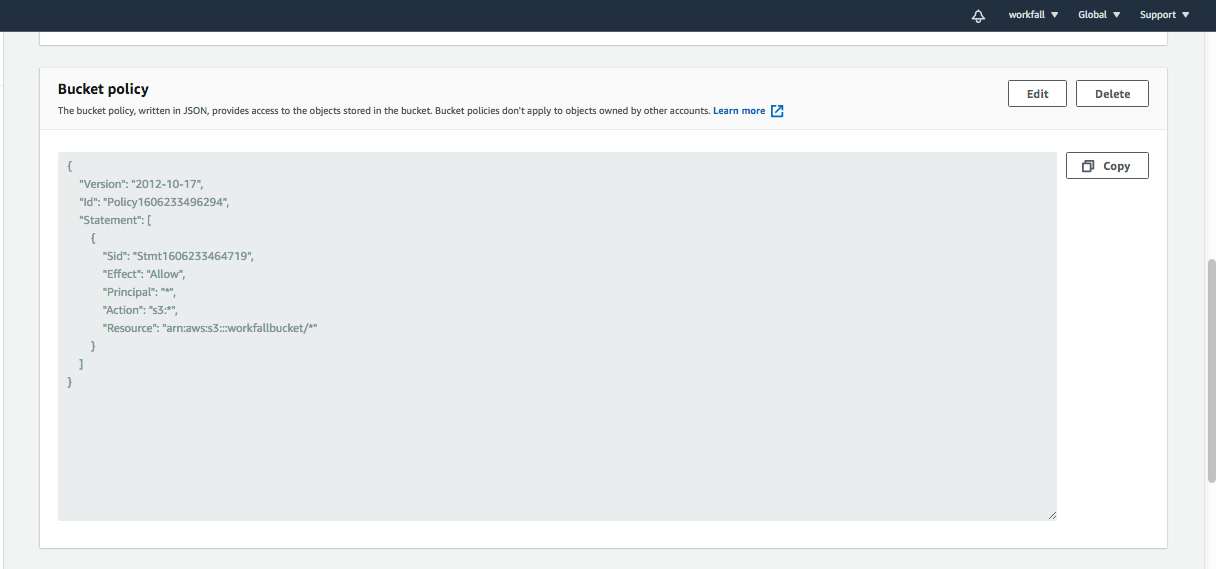
Now as you can see in the following image, our file is publicly available and we will be able to use this file for data analytics.
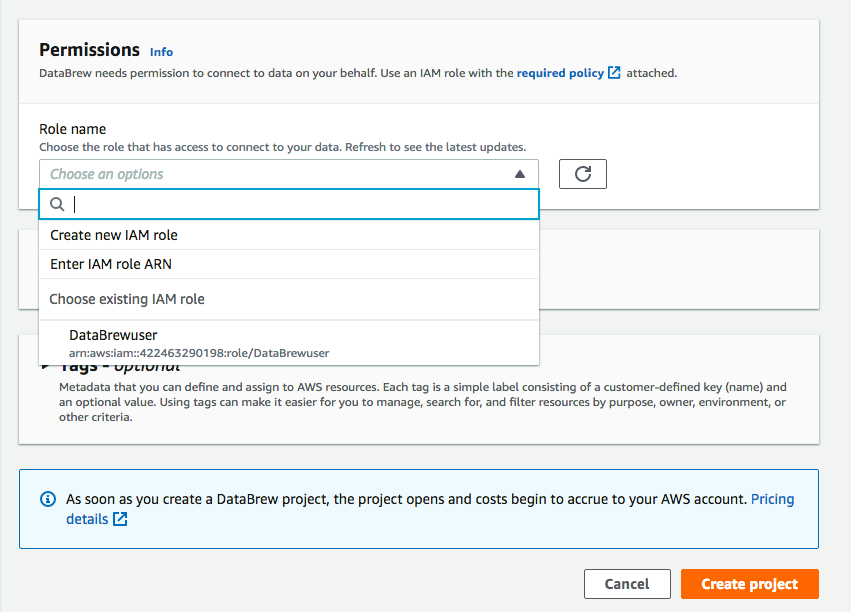
we have to make sure that the user has permission to use DataBrew. In the Access permissions, select an IAM role that provides DataBrew read permissions to my input S3 bucket. Only roles where DataBrew is the service principal for the trust policy are shown in the DataBrew console. To create one in the IAM console, select DataBrew as a trusted entity
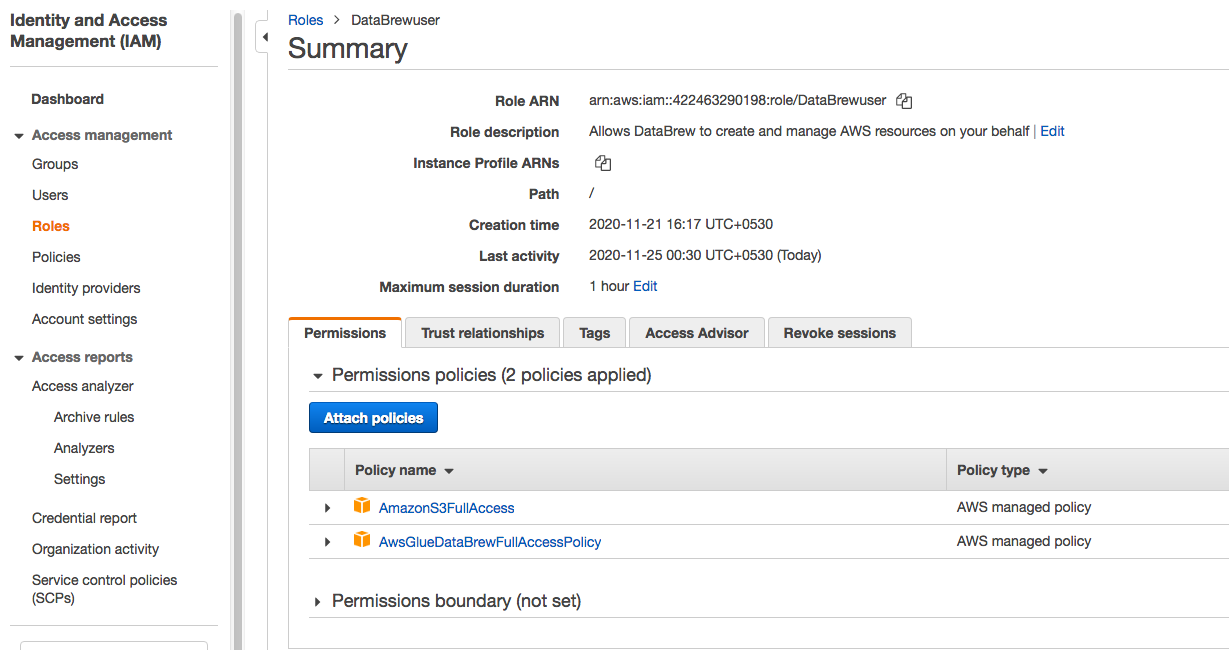
2. Provide DataBrew read permissions to S3 bucket.
To provide DataBrew read permission to read S3 buckets, you need to create a role that provides DataBrew read permissions to my input S3 bucket. As shown in the image below, create a new role named DataBrewuser and apply for two permissions as shown:
3. Create a DataBrew project to visually explore, understand, combine, clean, and normalize data in a dataset
Now time to use the DataBrew service to visualize the data. AWS DataBrew service is available in the following regions only:
- US East (N. Virginia)
- US East (Ohio)
- US West (Oregon)
- Europe (Ireland)
- Europe (Frankfurt)
- Asia Pacific (Tokyo)
- Asia Pacific (Sydney)
So before proceeding, we need to make sure that we choose Asia Pacific (Tokyo) as a region because we have created a bucket and uploaded a file in the same region.
From your AWS management console, find and select AWS Glue DataBrew service as shown in the following image:
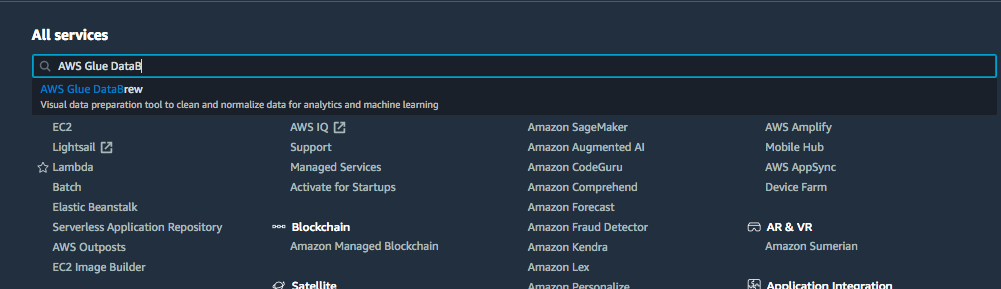
You will get the following. Let’s create our first DataBrew project by clicking on the Create Project button.
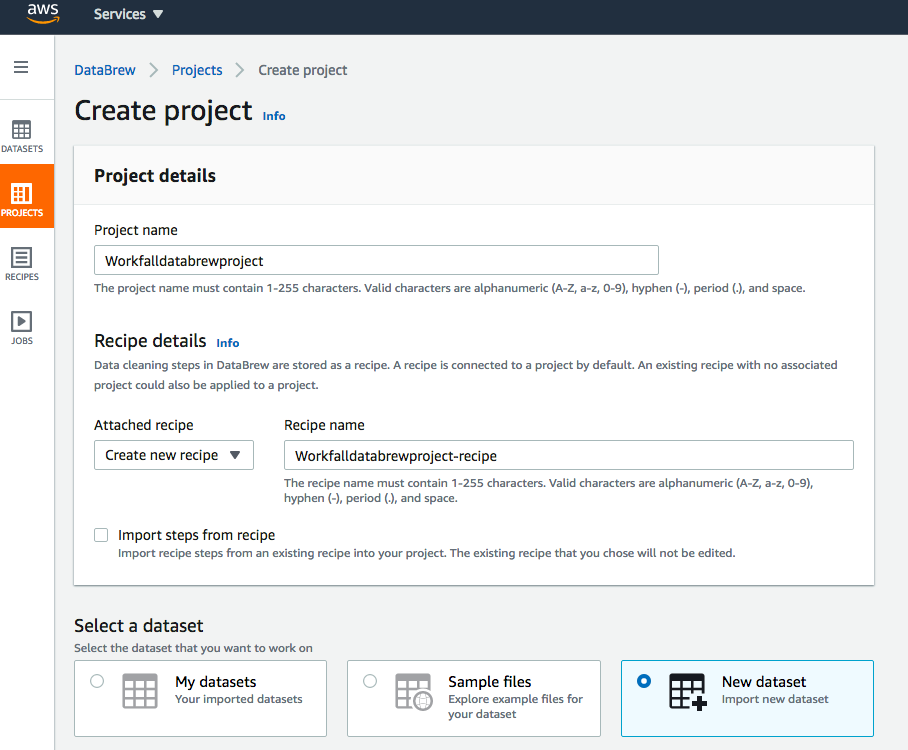
You will get the following screen. Enter the project name and choose New dataset from the Select a dataset options. (If you don’t have any dataset, you can proceed this exercise by selecting Sample files option also)
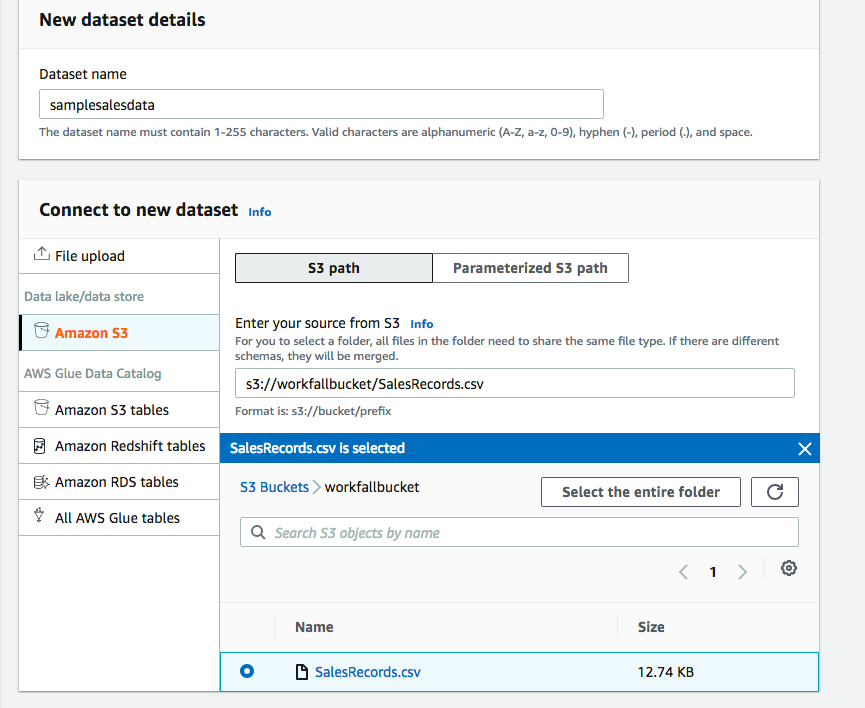
You can give the dataset name and choose a bucket that contains a data file as shown in the following image
Next, choose the role which we have created at the beginning of the exercise and click on the create project button.
It will take some time, and once the dataset is ready, you will get the following screen.
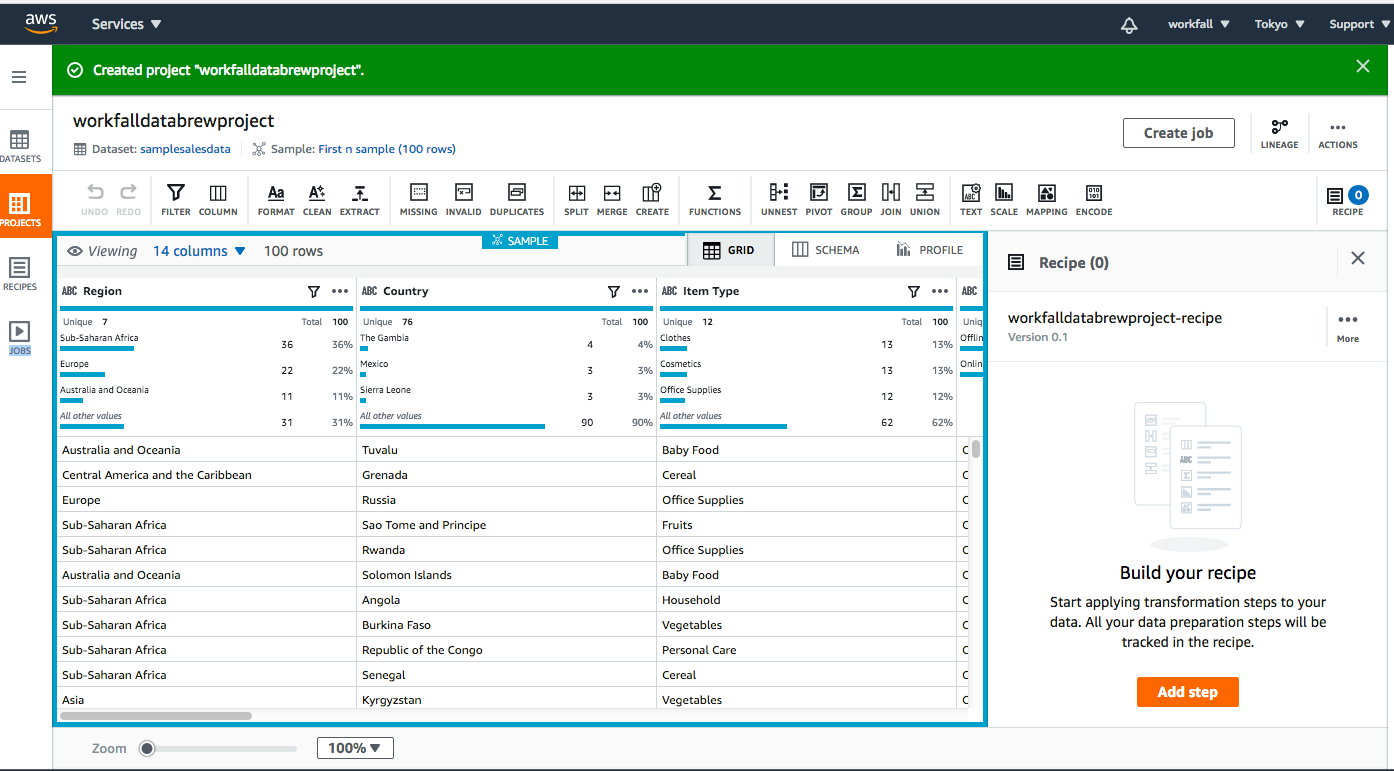
As you can see in the above image, the Grid view is the default when we create a new project. In this grid view, we can see the data as it has been brought in. There is a summary of the range of values that have been found for each column. The statistical distribution is provided for numerical columns.
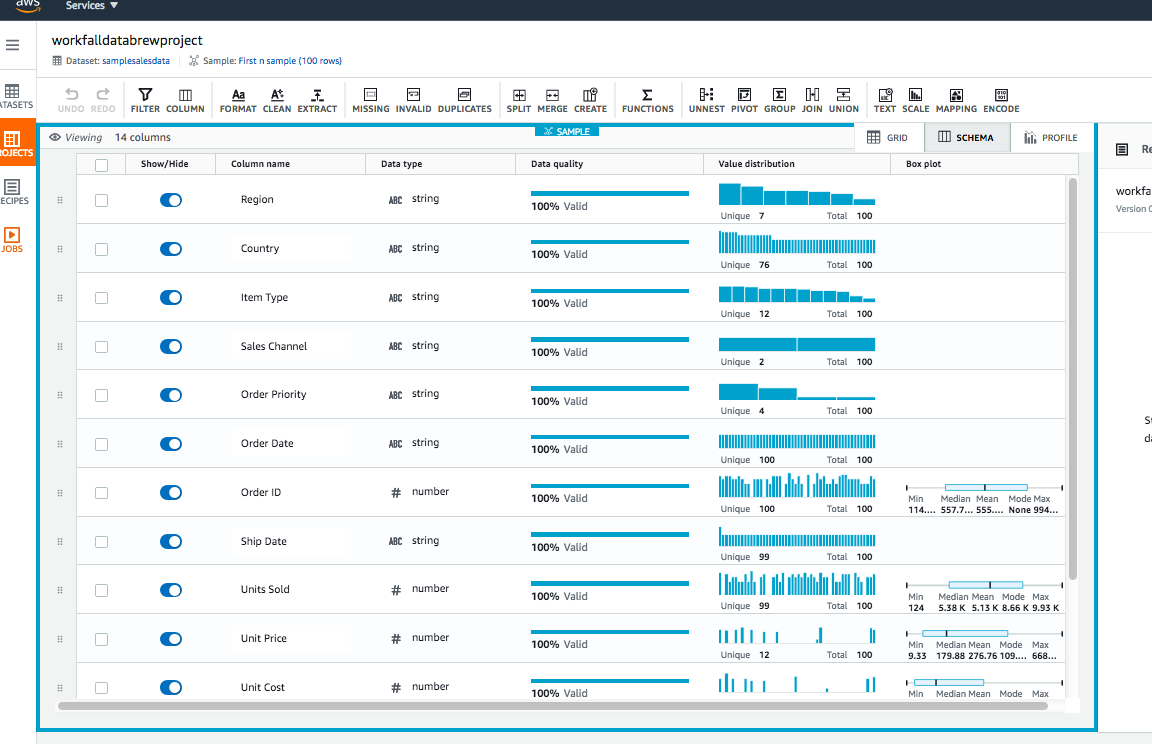
We can drill down on the inferred schema in the Schema view (as shown in the following image) and optionally hide some of the columns. We can see all of the data columns in the image below. (If you conceal a few columns and then return to grid view, you won’t be able to see the data in the hidden columns.)
In the Profile view (as shown in the following image), we can run a data profile job to examine and collect statistical summaries about the data. This is an assessment in terms of structure, content, relationships, and derivation. When the profile job has succeeded, we can see a summary of the rows and columns in our dataset, how many columns and rows are valid, and correlations between columns.
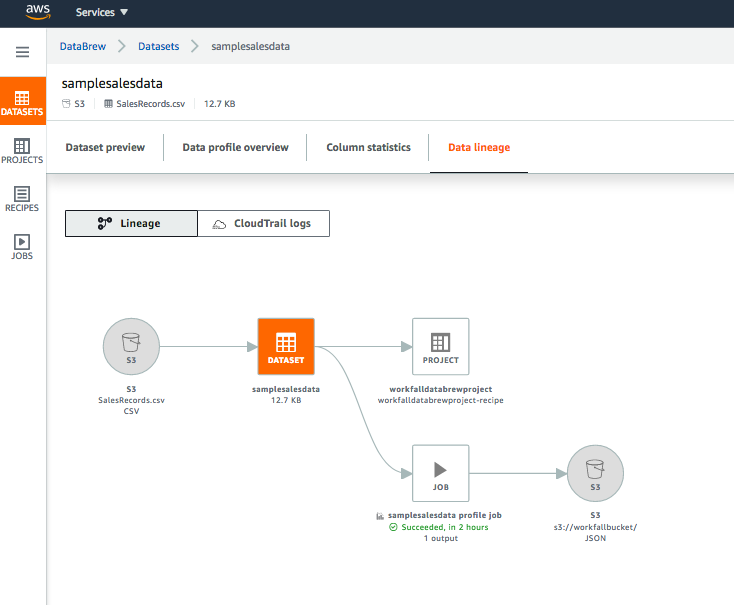
You can also check Data Lineage as shown in the following image:
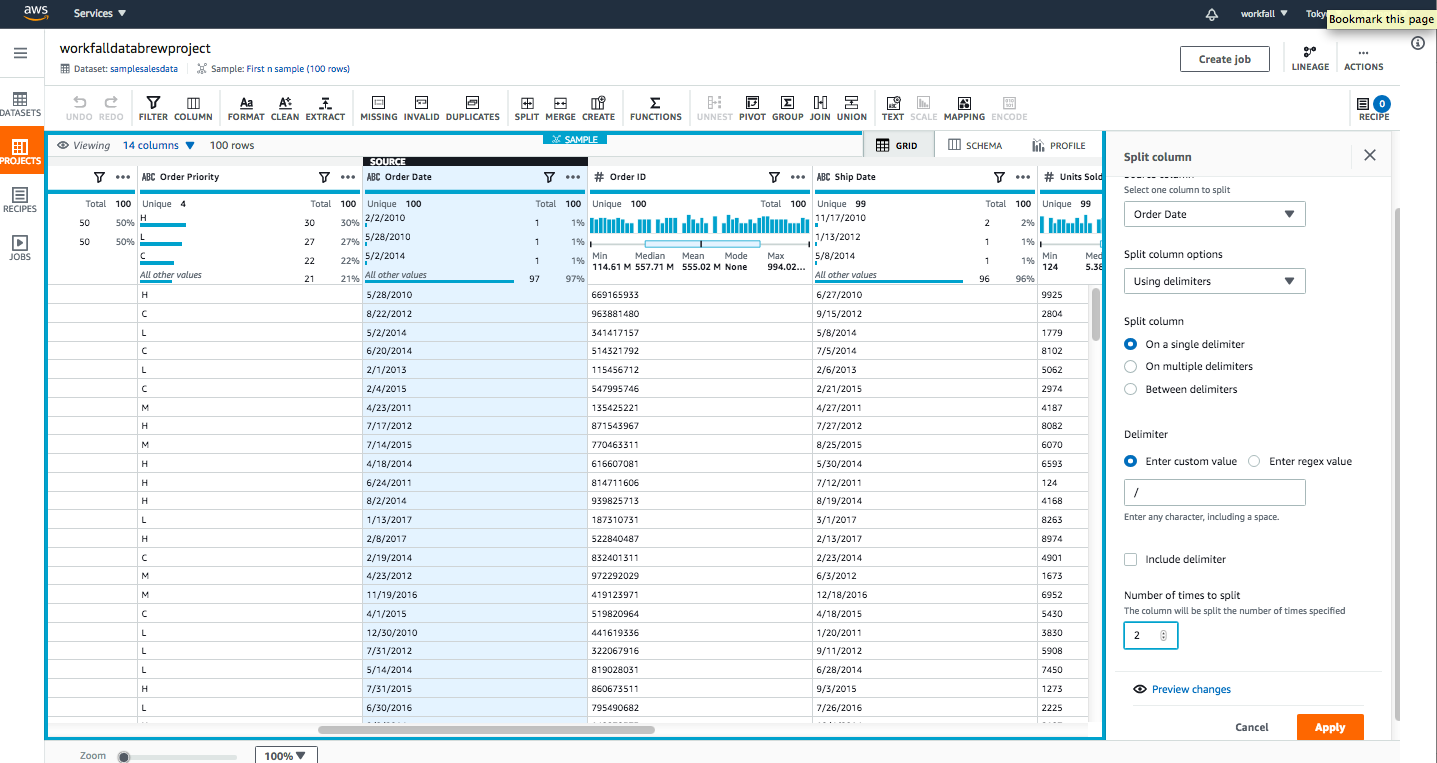
Let’s quickly work with how to split a column into multiple columns. In this dataset we have a column named Order Date, which I have split based on delimiter as shown in the below image:
After applying split functionality, this column will get divided into three columns as shown in the below image.
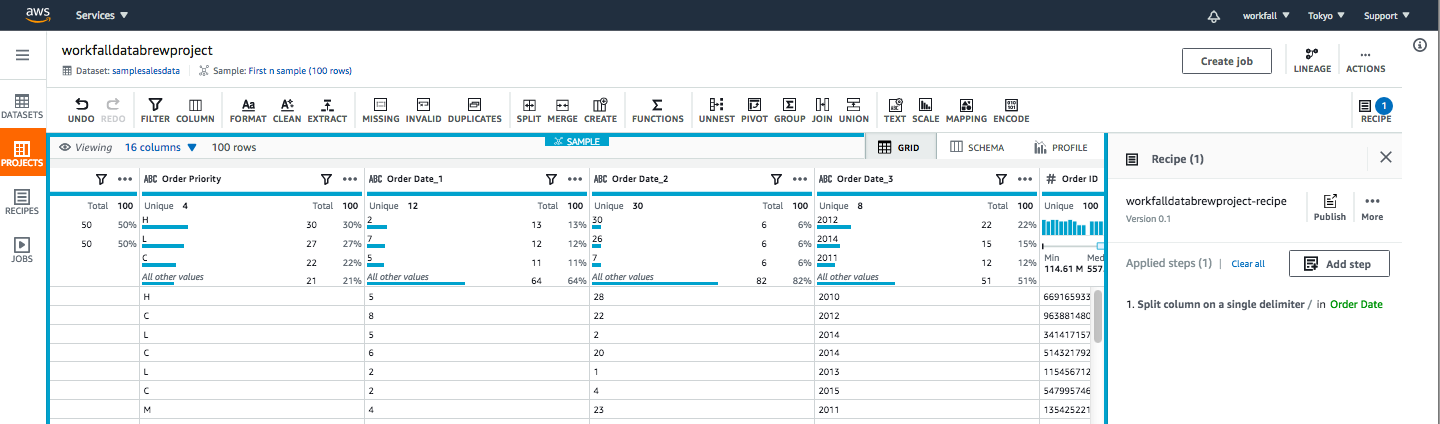
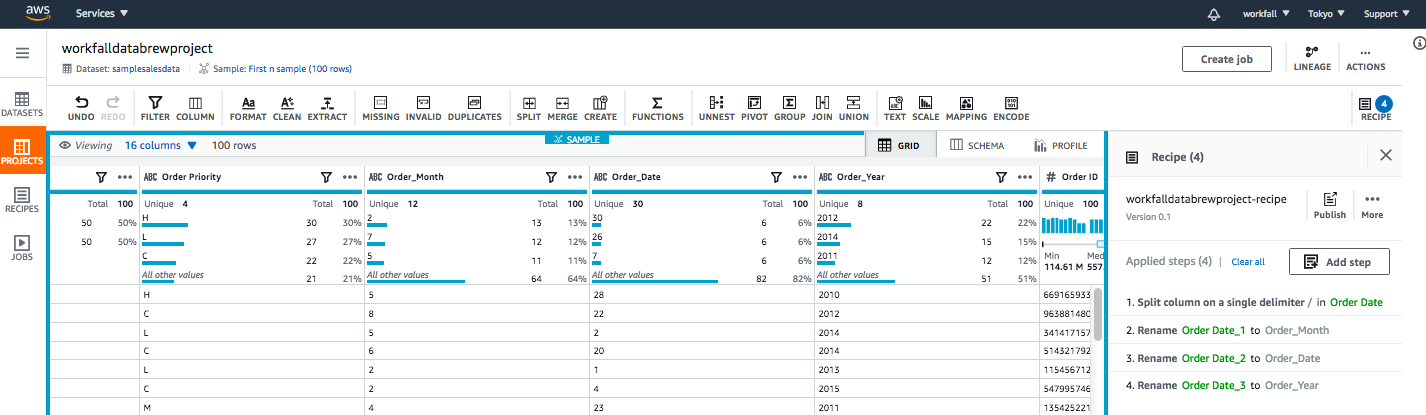
You can easily rename the columns by clicking on the columns heading, as shown in the following image:
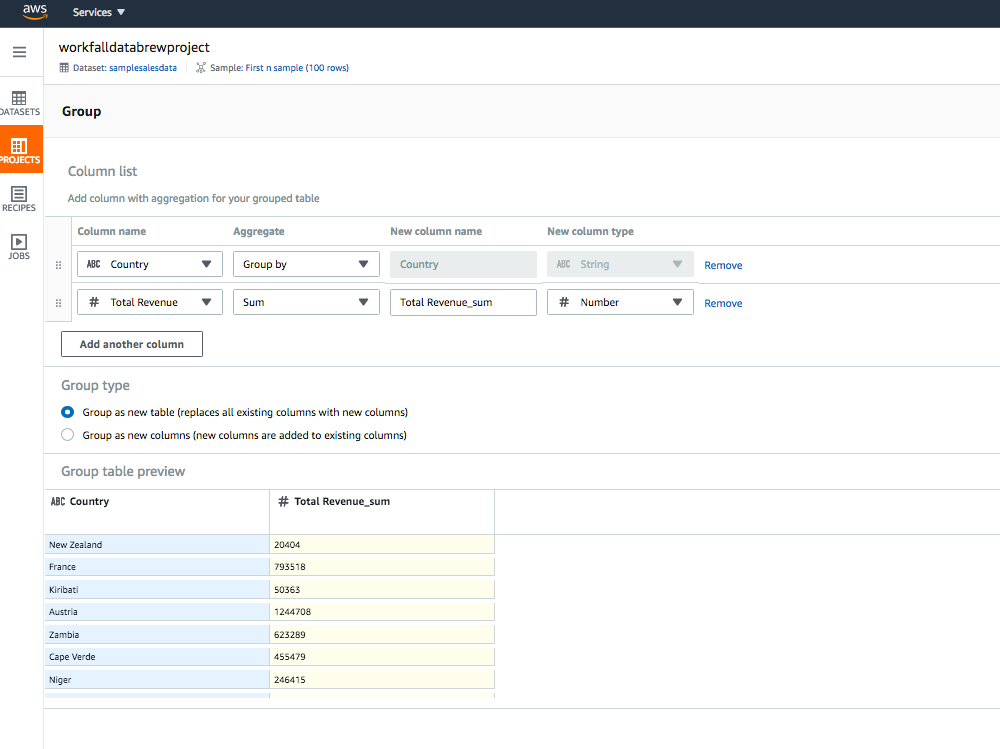
Let’s try how group functions work. Click on the Group icon in the grid view, you will get the group screen. to see country wise total revenue, choose the columns and functions as shown in the below image:
Now let’s run the job to save these data in the S3 bucket in two different formats as shown in the below image:
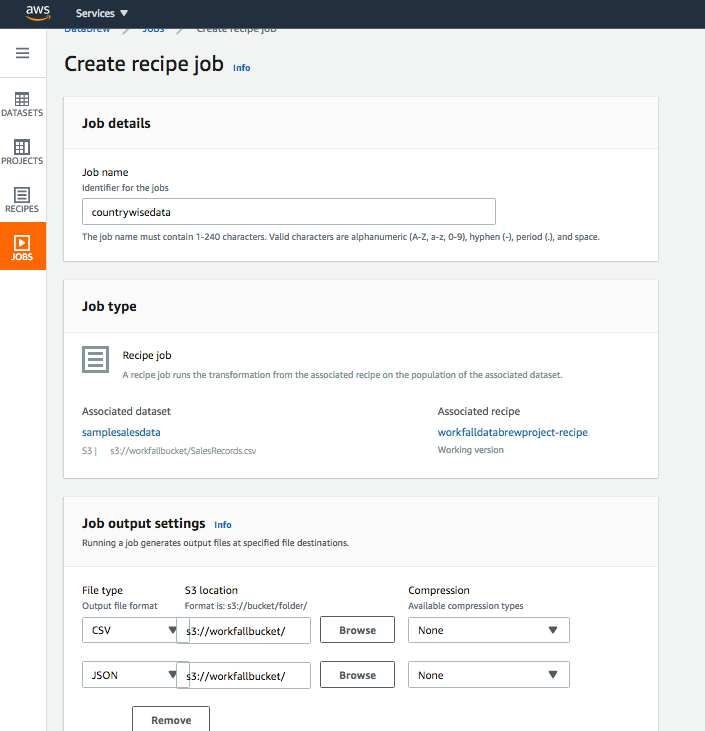
Select the role and then click on Create and Run Job button, you will be able to see the following image:
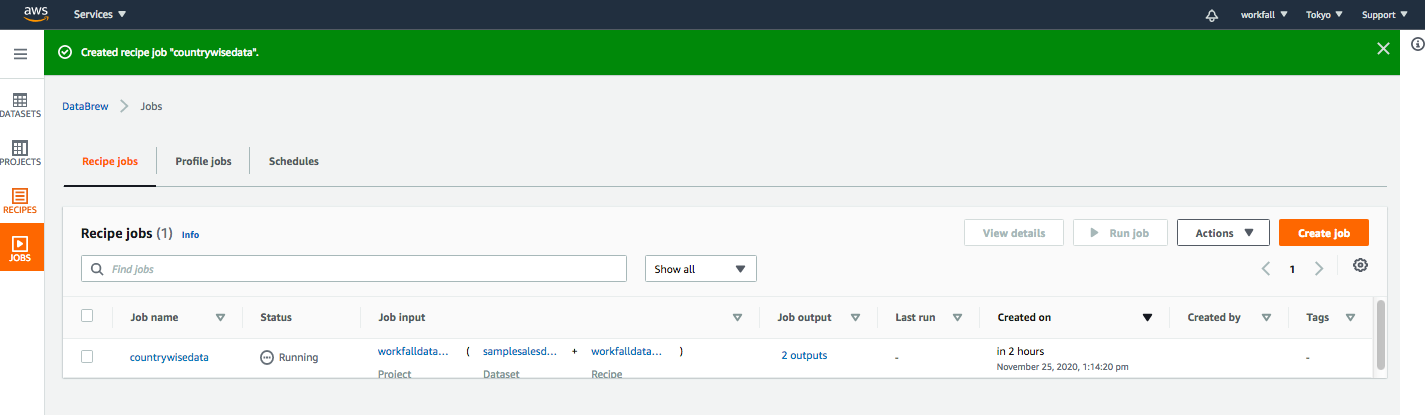
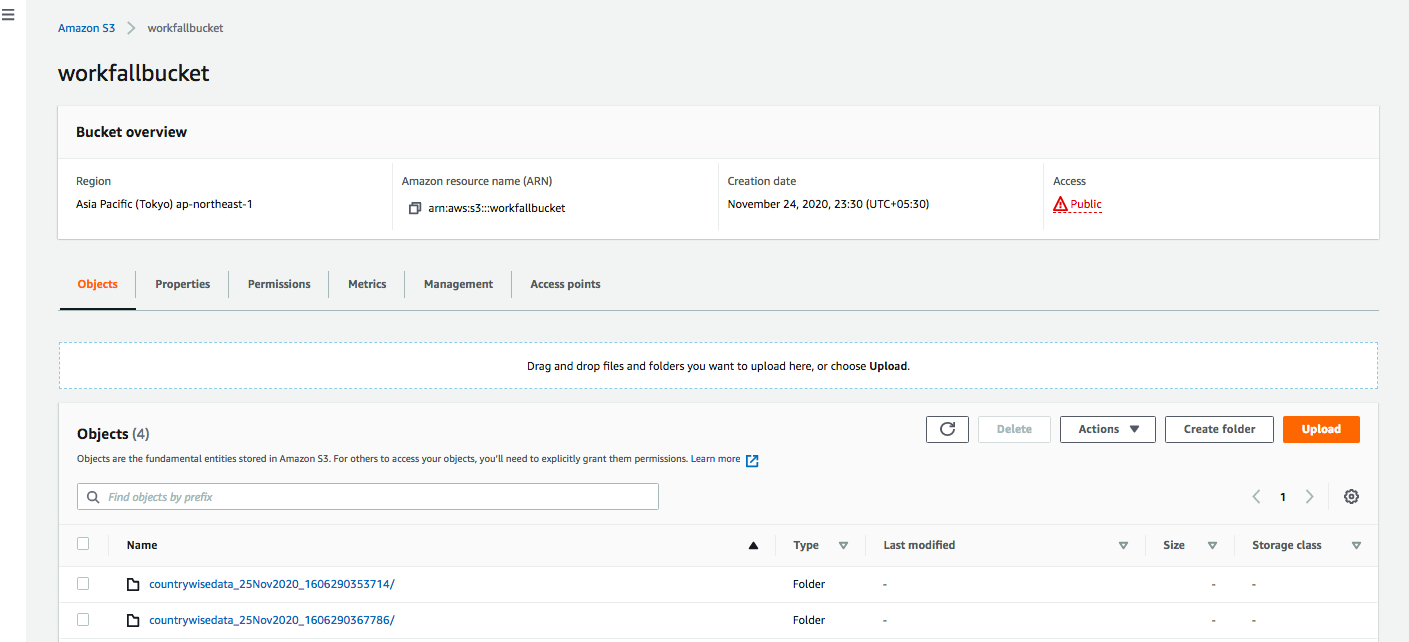
Once this job is finished, you will be able to see two folders containing relevant files into each inside your selected bucket as shown in the image below:
With the evolution of technology along with great tools for analysis available in the market currently, AWS DataBrew is arguably one of the easiest tools to prepare data for analytics, ML, and BI. Users can get the right insights for business without writing, maintaining, and updating code, simplifying the analysis, and getting accurate results.
Conclusion
In this blog, we have demonstrated a quick exercise on how to set up your first DataBrew project and how to do data analytics easily. Stay tuned to keep getting all updates about our upcoming new blogs on AWS and relevant technologies.
Meanwhile …
Keep Exploring -> Keep Learning -> Keep Mastering
This blog is part of our effort towards building a knowledgeable and kick-ass tech community. At Workfall, we strive to provide the best tech and pay opportunities to AWS-certified talents. If you’re looking to work with global clients, build kick-ass products while making big bucks doing so, give it a shot at workfall.com/partner today.


